Des informations essentielles pour les visiteurs et visiteuses à la recherche d'un ouvrage ou article spécifique. Ces meta)données étoffent les catalogues, "habillent les livres". Outres une couverture, elles rappellent le contexte d'édition, l'année de publication, les codes barre (ISBN,EAN), l'origine physique et située des ressources consultées : leur matérialité d'origine, leur conditions de production. Pour autant, comme souvent avec la valorisation de la marchandise, les moyens de production, le travail, les intermédiaires, sont invisibilisés.
Meta search engine :
fédérer plusieurs moteurs de recherche
annas-archive s'est constituée à partir de fonds préexistants (bibliothèques/bases de données). On peut ainsi la concidérer comme un /g/meta-moteur/ de recherche totalisant plusieurs sets (ensembles) de données. C'est le cas du projet annas-archive qui met en avant dans ses résultat des liens de téléchargement vers des serveurs partenaires ou internes et vers d'autres sites/bibliothèques de l'ombre. On est donc face à une multiplicité des sources/origines de fichiers, une diversité qui augmente l'accessibilité et la durée de vie des liens. Cette approche montre une volonté de fédérer plusieurs fonds, une ambition archivistique qui prend soin d'indiquer d'où viennent les données et d'expliciter/rendre visible comment elles sont structurées au sein de son propre écosystème.
Pour comprendre le fonctionnement d'un meta-moteur de recherche, pernnons un exemple. Depuis la page la page d'accueil, nous pouvons lanccer une recherche en entrant un ISBN (un référent numérique attribué à un livre à sa sortie, son matricule). Si un resultat remonte nous pouvons cliquer sur l'entrée qui nous convient/interesse. Une seconde page s'ouvre avec plusieurs informations. On trouve une desciption texutuelle, la converture de l'ouvrage et autres metadonnées essentielles tel le nom de l'auteur, la date de publication. On retrouve l'ISBN/EAN ainsi qu'une mutlitude d'autres identifiants pointant vers ce même objet (livre/revue) mais sur différentes bases de données/sites : selon des nomencaltures spécifiques. Chaque projet d'indexation (légal ou non) propose sa propre façon de nomer les choses/objets, de les identifier comme unique afin d'en définir l'origine.
Mais, ici, annas-archive nous indique le lien vers différents espaces de sa base de donnée, segmentée selon des data-sets distincts. Dans notre exemple, on retrouve un lien direct vers Open Library, une référence à OCLC/WorldCat (scrappé par AA), un identifiant Library of Congress Classification, un lien torrent (qui contient cet ouvrage), etc. On saisi un peu les impératifs techniques d'une telle entreprise archivistique, automatisant les indexations, raffinant les résultats.

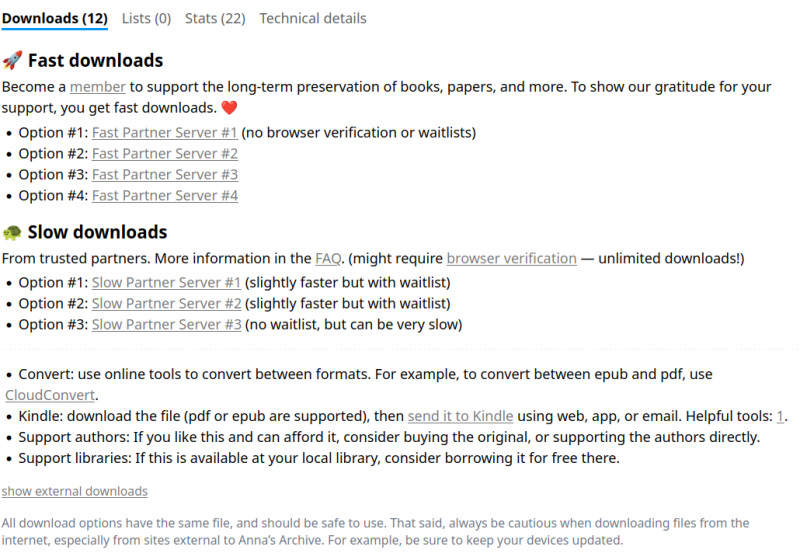
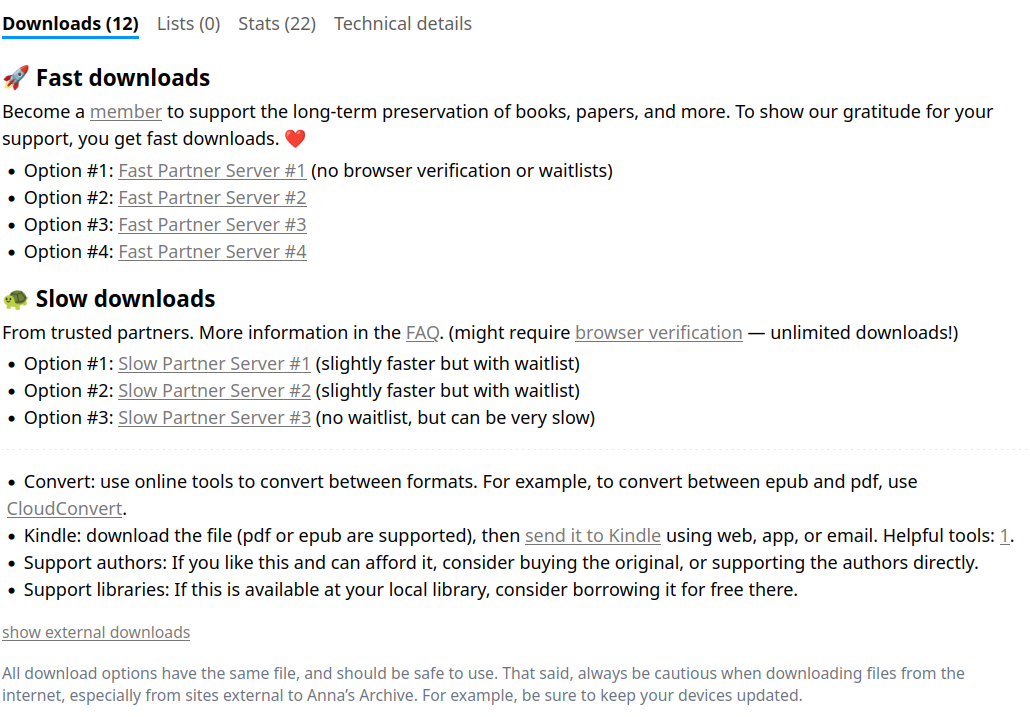
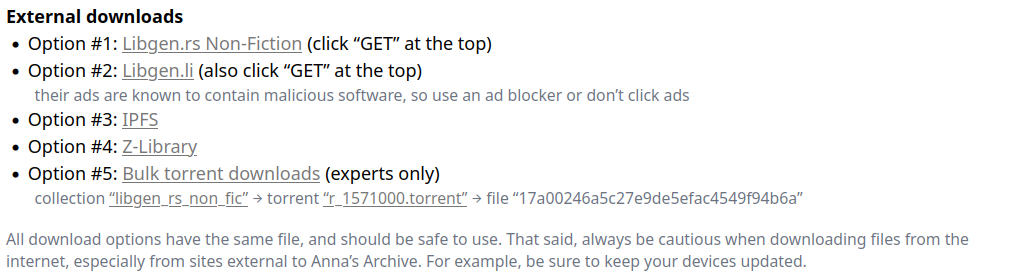
En bas de page on nous indique les liens vers des serveurs partenaires permettant de télécharger un fichier. Des liens "lents" et d'autres rapides, nécessitant de s'inscrire/d'être membre, d'avoir payé un abannement/contribution. Les liens "externes" ne sont pas visibles directement (cachés), il faut cliquer sur "Show external downloads" pour accéder à ces liens de téléchargement prioritaires. Certains pointent vers LibGenenis (l'un des fonds les plus important durant des années) ou Sci_Hub, d'autres vers Z_library ([dont il sera davantage [[question ici|/a/bdl/bibliotheques/anna_zlib_worldcat/]]]).. Enfin, des copies mirroires de ces ressources (au bout du lien) sont présentes sur les propres serveurs de annas-archive.
Pour d'autres aperçus visuels de ces biliothèques :
- /a/bibliotheques/anna_zlib_worldcat/captures_ecran_aa_wc/
- /a/bibliotheques/anna_zlib_worldcat/captures_ecran_zlib/
Le projet d'indexer tous les savoirs présents et passés nous fait pensé au fantasme (exercice de pensé proposé par Louis_Borges : une bibliothèques contenant tous les savoirs existants ou à venir, qu'une intelligence numérique pourrait auto-générer. version_3D 2016]